
 首页 > 资源中心 > FAQ
首页 > 资源中心 > FAQ 1、 问题场景
在声明那些不应该被编译器优化的变量时,JNH官网一般会选择使用 volatile 关键字,否则,编译器可能会优化对该变量的访问,从而生成意外的代码,或移除预期的功能。因此,对于 volatile 关键字的使用,以及它对编译器优化的影响,都值得进行详细的了解和学习。
2、软硬件环境
1)、软件版本:MDK5.40
2)、电脑环境:Windows 10
3)、外设硬件:无
3、解决方法
1)、没有加volatile关键字时,函数的反汇编表现如图1所示:
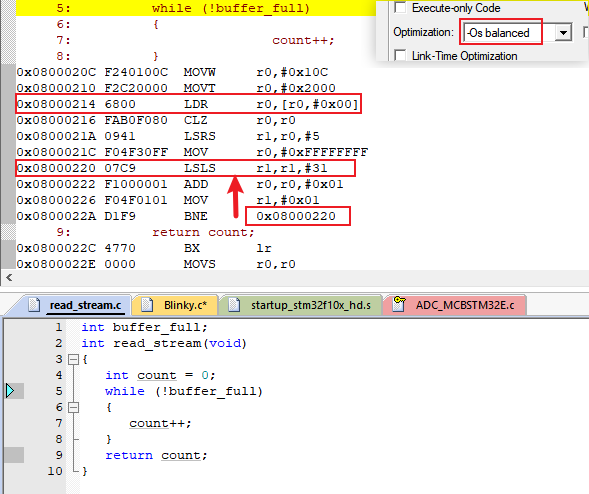
图 1
反汇编解读:
0x0800020C F240110C MOVW r0, #0x10C
0x08000210 F2C20100 MOVT r0, #0x2000
这两句指令将变量 buffer_full 的地址加载到寄存器 r0 中,此时 r0= 0x200010C,后续方便直接从这个地址读取数据。
0x08000214 6800 LDR r0,[r0,#0x00]
这里是从 r0 存储的内存地址里 (即 buffer_full 的地址)读取值,并保存值到寄存器 r0。即读取 buffer_full 的当前值。
0x08000216 FAB0F080 CLZ r0,r0
这里是计算 r0 的前导零的数量,并把这个数量存储在 r0 中。
(CLZ 指令会从最高有效位(最左侧的位)开始计算连续的零。对于全零的值,所有 32 位都是零的,会输出 32。举例:如果执行 CLZ 前 r0=0x0000 0000,那么执行后 r0=32。如果执行 CLZ 前 r0=0x8000 0000,那么执行后 r0=0)
0x0800021A 0941 LSRS r1,r0,#5
这里是将 r0 右移 5 位后的结果存入 r1。因为此时 r0=32,即 0x0000 0020。右移 5 位后,即变成了 0x0000 0001,所以 r1 此时为 0x0000 0001
0x08000220 07C9 LSLS r1,r1,#31
这里是将 r1 左移 31 位,r1 此时就变成了 0x1000 0000, 这个值会触发程序状态寄存器自动更新一些标志位,比如这里会自动更新后面会用到的 Z 标志位,即零标志位,因为此时 r1 里的值不为 0,那么 Z 标志位就会被自动置为 0。
现在,就相当于有了一个标志位 Z 表示 buffer_full 这个变量为 0 了,后续的 BNE 其实就是判断这个 Z 标志位。
(通过 CLZ 数出前导 0 的个数,先右移 5 位,再左移 31 位后,即可通过标志位判断变量是否为全 0。)
0x0800021C F04F30FF MOV r0, #0xFFFFFFFF
这里相当于初始化代码中的 count 值,也是为了方便后续操作。
0x08000222 F1000001 ADD r0,r0,#1
这里是将 count 对应的寄存器 r0 加 1,对应循环体中执行的 count++ 操作。
0x08000226 F04F0101 MOV r1,#1
这里是将 r1 重新设置为 1,为下次循环使用。保证了下一次进入循环时,r1 是一个可控的初始值。因为下一条指令是 BNE,如果 BNE 判断变量为 0,就要跳转到 0x08000220 继续循环,而 0x08000220 地址需要执行 r1 左移 31 位,所以这里是为了循环而考虑设置的指令。
0x0800022A D1F9 BNE 0x08000220
这里是,如果 BNE 通过 Z 标志位判断出 buffer_full 为 0,则跳转回地址 0x08000220 继续循环。
2)、加了volatile关键字时,函数的反汇编表现如图2所示:

图 2
反汇编解读:
0x0800020C F240110C MOVW r1, #0x10C
0x08000210 F2C20100 MOVT r1, #0x2000
这两句指令将变量 buffer_full 的地址加载到寄存器 r1 中,此时 r1= 0x200010C,后续方便直接从这个地址读取数据。
0x08000210 F04F30FF MOV r0, #0xFFFFFFFF
这里相当于初始化代码中的 count 值,也是为了方便后续操作。
0x08000218 680A LDR r2, [r1, #0x00]
从 r1 存储的内存地址里 (即 buffer_full 的地址)读取值,并保存值到寄存器 r2。即读取 buffer_full 的当前值。
0x0800021A 3001 ADDS r0, r0, #0x01
将 count 对应的寄存器 r0 加 1,对应循环体中执行的 count++ 操作。
0x0800021C 2A00 CMP r2, #0x00
将 r2(即 buffer_full 的值)与 0 进行比较。这里比较完 2 个数值后,也会更新程序状态寄存器里的标志位,其实也是 Z 标志位,如果 2 个被比较的数值是相同的,Z 就会等于 1,Z=1 就会使下一条指令 BEQ 跳转到指定的地址,去开启新一轮的循环。
0x0800021E D0FB BEQ 0x08000218
通过判断 Z 标志位,来确定 buffer_full 是否为 0。
如果 buffer_full == 0,跳转到地址 0x08000218(重新执行循环)。
如果 buffer_full != 0,跳出循环,执行后续逻辑。
3)、比较有无关键字时的编译器行为
问 ①:很明显可以看到,图 1 中的代码,不加 volatile 时,反汇编代码其实会长一些,为什么会多出来这么多指令呢?
答 ①:其实是因为不加 volatile,编译器就会假设!!!它会假设要判断的变量值,在该函数运行时不会改变,所以就会使用更少的寄存器(2 个寄存器),更简单的位操作(即:导致代码稍微增多的原因),来实现他认为相同的判断和循环功能。而加了 volatile 以后,他就会使用 3 个寄存器和略微高级的指令,来完成判断和循环功能。
问 ②:那么为什么不加 volatile 会少用 1 个寄存器而增加一些汇编代码,加了 volatile 会多用 1 个寄存器而减少汇编代码呢?
答 ②:因为 Os 等级的优化。Os 优化等级会导致:编译器要考虑提高执行效率,因为这个 Os 优化等级他是想要在减少代码量和提高执行效率上做权衡的。
所以,判断变量是否为 0 这个操作,他能用 2 个寄存器,就用 2 个,不多占另外的寄存器,让出空闲的寄存器给更复杂的功能,提高效率。
而且他增加的指令,都是最简单的位操作,不是复杂的汇编指令,所以对于流水线的利用会更加充分,所以这里虽然相比于加了 volatile 后所增加的一点点代码(其实相比于 O0 优化等级,已经减少了汇编代码量),但是换来了更快的执行速度,空出了更多的寄存器给接下来的功能使用,是一种非常有大局观的权衡之策。
最后,加了 volatile 后,编译器明显变得谨慎了,他很害怕,因为他知道加了 volatile 关键字的变量,是随时可能被外界更改的,他不敢再进行大量的位操作去判断变量是否为 0 了,因为很有可能在执行这些位操作时,这个变量就被别的任务更改了,他必须在获取到变量最新值时,立马执行判断,这样才能获取到正确的比较结果。
问 ③:加了 volatile 后,他本身带来的好处显现在哪里?
答 ③:图 1 中,可以看到,他第一次判断完 buffer_full 为 0 以后,就循环使用那个判断结果,根本就不再从原始的地址取数对比了。而在图 2 中,循环时,函数很明显跳回到了 LDR 指令那里,LDR 会从变量的内存地址中重新取数,确保每次使用的都是从内存中取出的最新值。


